OpenAI анонсировала модель o3
Достижения в тестах
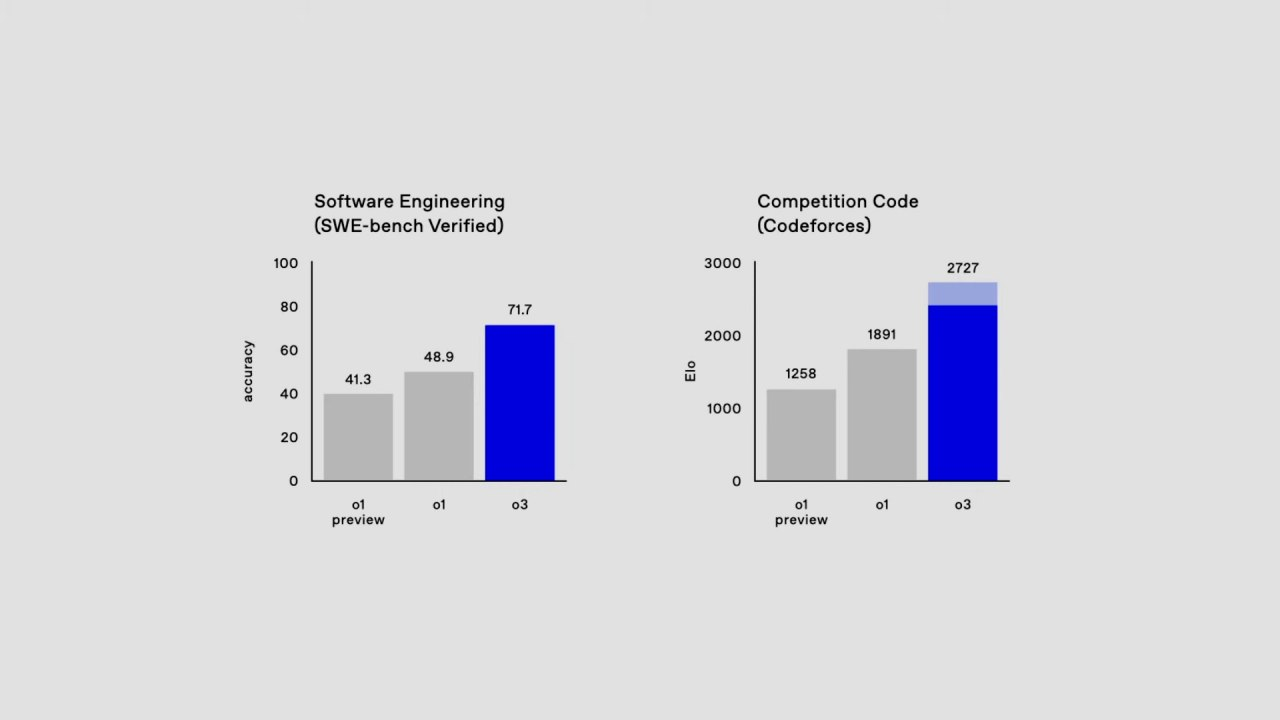
Рейтинг 2700+ на CodeForces
Модель достигла уровня топовых программистов, показав способность решать сложные алгоритмические задачи. CodeForces — это одна из самых известных платформ для соревнований по программированию, где подобный рейтинг позволяет войти в элиту мировых программистов.
Судя по бенчмаркам, эта модель может кодить на уровне сеньора.
71,7% на SWE-bench (тестирование в области программной инженерии)
SWE-bench — это тестовый набор задач для оценки уровня профессиональных знаний в программной инженерии. Модель превосходит большинство участников с реальным опытом работы в индустрии, демонстрируя понимание архитектуры программного обеспечения, алгоритмов и структур данных.
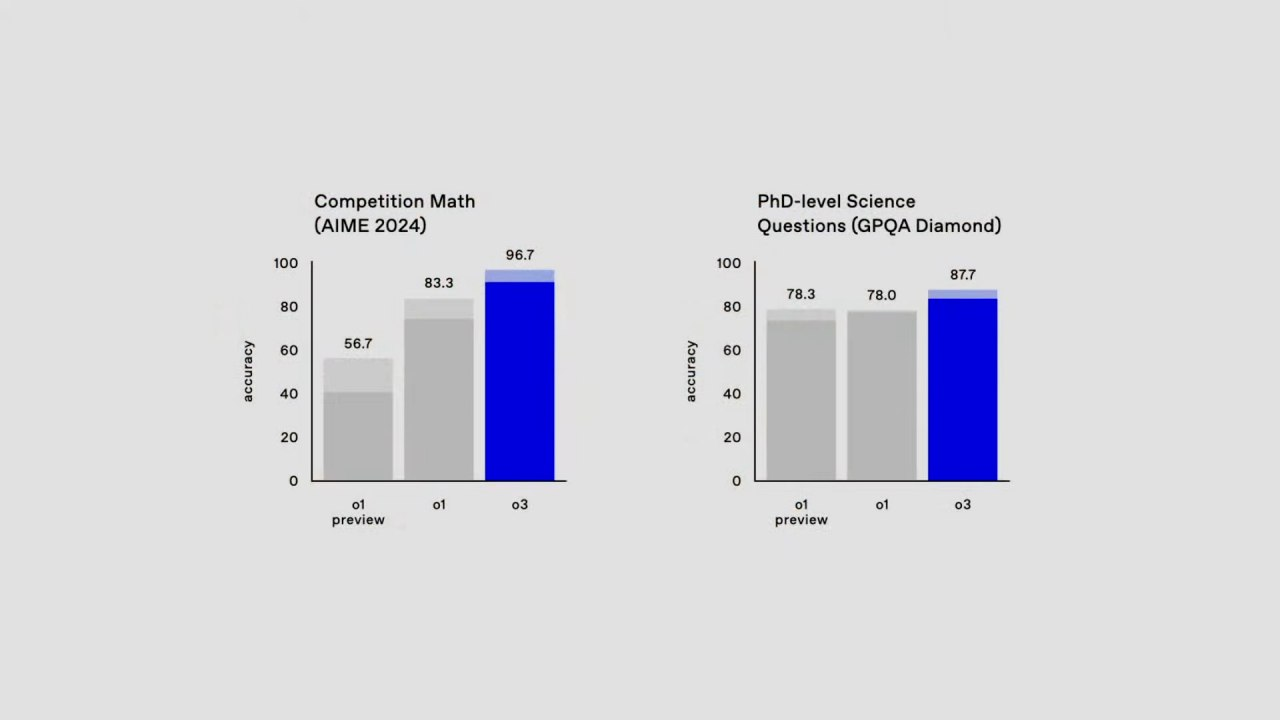
96,7% точности на математическом тесте AIME 2024
AIME (American Invitational Mathematics Examination) — это математическая олимпиада, известная своей сложностью. Данный результат близок к идеальному, что демонстрирует выдающиеся способности модели в решении задач высокого уровня.
87,7% на вопросах уровня PhD GPQA Diamond
Модель успешно отвечает на вопросы, требующие глубокой теоретической подготовки, эквивалентной докторантуре. Этот результат отражает сильную компетенцию в генерации точных и сложных ответов.
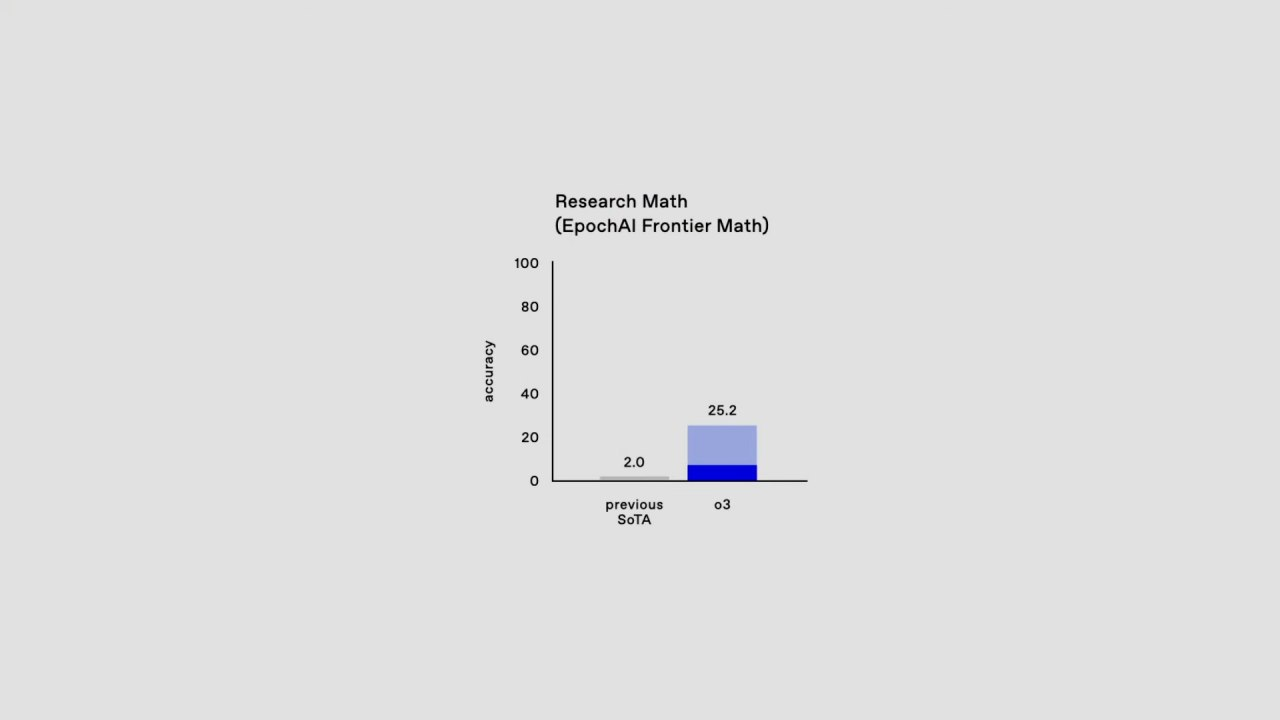
25,2% на сверхсложном EpochAI Frontier Math (рост с 2%)
EpochAI Frontier Math — это тест для оценки ИИ на сложнейших задачах, выходящих за рамки стандартных математических навыков. Прогресс модели с 2% до 25,2% подчеркивает значительное улучшение в решении задач, которые традиционно считались трудными даже для ИИ.
Прорыв в логическом мышлении
87,5% на закрытой оценке ARC-AGI
ARC-AGI (Abstraction and Reasoning Corpus for AGI) — это один из самых строгих и закрытых тестов, предназначенных для оценки уровня абстрактного мышления и способности к рассуждениям. Высокий результат свидетельствует о том, что модель способна решать задачи с минимальными данными и без прямого обучения на них.
Улучшение производительности в 3 раза по сравнению с моделью o1
Новая архитектура и оптимизация позволили достичь тройного прироста производительности, делая модель более эффективной в решении разнообразных задач.
Подтвержденная эффективность на совершенно новых задачах
Модель продемонстрировала способность решать задачи, с которыми ранее не сталкивалась, что подтверждает её универсальность и отсутствие зависимости от заучивания ответов.
Без запоминания — чисто логические способности
Достижения основаны на способности к рассуждению, а не на запоминании данных. Это важное отличие от моделей, которые лишь "запоминают" шаблоны решений.
Технические достижения
Создана на основе масштабированного обучения с подкреплением (RL)
Использование RL позволило улучшить способность модели оптимизировать свои решения, адаптироваться к сложным сценариям и извлекать пользу из тренировок на сложных задачах.
Самая ресурсоемкая модель на этапе тестирования)
Для достижения текущих результатов использовались масштабные вычислительные мощности, что позволило модели демонстрировать выдающиеся способности даже в самых сложных тестах.
Представлена эффективная версия o3-mini
Вместе с основной моделью представлена уменьшенная версия o3-mini. Она разработана для пользователей, которым требуется высокая производительность при меньших ресурсах.
Устанавливает новые стандарты по всем техническим метрикам
o3 превосходит предыдущие модели и конкурентов по всем основным показателям, устанавливая новые стандарты качества и производительности.
Влияние на индустрию
Открывает новую эру в масштабировании ИИ
Масштабирование вычислительных мощностей и архитектуры модели позволяет значительно расширить границы возможностей искусственного интеллекта.
Демонстрирует эффективность увеличения вычислительной мощности
Результаты подтверждают, что вложения в вычислительные ресурсы и усовершенствование архитектуры модели оправданы и ведут к реальному прогрессу в ИИ.
Ожидается снижение цен на токены
Внедрение новых технологий и оптимизации может привести к удешевлению обработки запросов, что сделает доступ к ИИ более демократичным.
Производительность моделей семейства "O"
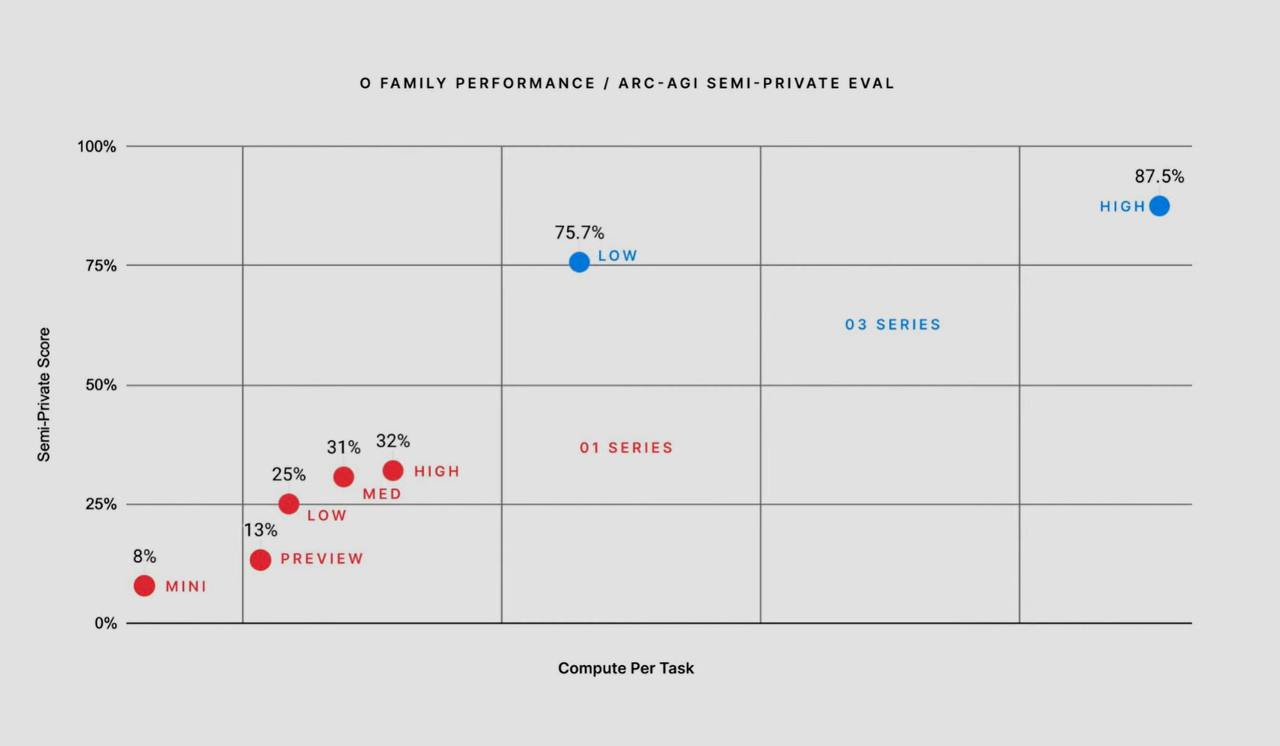
Semi-Private Score (вертикальная ось) — это показатель производительности на определённом тестовом наборе, связанный с задачами абстрактного мышления и обобщения (например, ARC-AGI). Чем выше значение, тем лучше модель справляется с этими задачами.
Compute Per Task (горизонтальная ось) — это объем вычислительных ресурсов, необходимых для выполнения одной задачи. Чем дальше вправо, тем больше ресурсов требуется.
Сегодня дают доступ ресёрчерам безопасности к o3-mini, простым смертным доступ к o3-mini дадут в конце января, к o3 чуть позже.
Что можно увидеть из графика?
Рост производительности:
Модели o3 находятся в правой верхней части графика, показывая явный скачок в результатах (87.5%) по сравнению с o1 которые располагаются внизу. Это демонстрирует, что новая архитектура и подходы к обучению обеспечивают качественные улучшения.
Соотношение производительности и затрат:
Ожидаемо, что лучшие результаты требуют большего объема вычислений. Тем не менее, модель o3 показывает хорошую оптимизацию: её прирост производительности (87.5%) значительно выше, чем можно было ожидать с учётом используемых ресурсов.
Ссылка на презентацию от OpenAI (на английском языке)